以前はアプリケーションの設定ファイルに単純なテキストである、INIファイルを用いていたアプリケーションも多かったですが、最近はXML(Extensible Markup Language:拡張可能なマーク付け言語)で記述された設定ファイルを用いたアプリケーションもよく見かけますネ。
先日インストールしたBoostにもXMLファイルの読み込みライブラリがあります。
今回はこのXMLファイルの読み込みについて遊んでみます!
何が必要なのか確認しよう!
XMLファイルの読み込みは静的ライブラリ不要、ヘッダーファイルのみで利用することができます。
| ヘッダーファイル | boost/property_tree/xml_parser.hpp |
サンプルプログラムを作ってみよう!
早速、サンプルプログラムで動かし方を見てみましょう。
今回は以下のXMLファイルを読み込んで内容を表示させてみましょう。
|
0 1 2 3 4 5 6 |
<?xml version="1.0" encoding="utf-8"?> <book-list> <book ISBN="9784873117362"> <title>Effective Modern C++</title> <author>Scott Meyers</author> </book> </book-list> |
最初のポイントはすべて英語で記述しており、日本語がない点です。
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
#include <iostream> #include <string> #include <boost/property_tree/xml_parser.hpp> int main() { boost::property_tree::ptree pt; boost::property_tree::xml_parser::read_xml("booklist.xml", pt); // <book-list> <book> の属性"ISBN" を取得 if (boost::optional<long long> isbn = pt.get_optional<long long>("book-list.book.<xmlattr>.ISBN")) std::cout << "ISBN : " << isbn << std::endl; // <book-list> <book> <title> を取得 if (boost::optional<std::string> title = pt.get_optional<std::string>("book-list.book.title")) std::cout << "TITLE : " << title << std::endl; // <book-list> <book> <author> を取得 if (auto author = pt.get_optional<std::string>("book-list.book.author")) std::cout << "AUTHOR : " << author << std::endl; return 0; } |
きちんと表示されていますネ!
属性の取得を行う場合、<xmlattr>と指定する必要があるところは少し気を付けないといけないです。
日本語にしてみる!
XMLファイルの中身が日本語だとどうなるでしょうか。
|
0 1 2 3 4 5 6 |
<?xml version="1.0" encoding="utf-8"?> <book-list> <book ISBN="9784774185194"> <title>栢木先生の基本情報技術者教室</title> <author>栢木厚</author> </book> </book-list> |
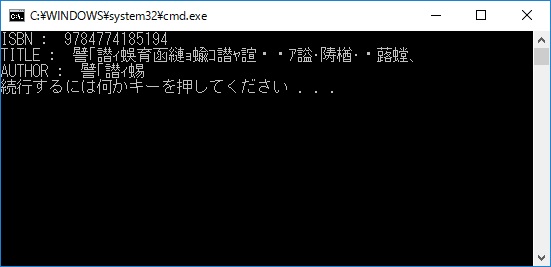
文字化けしました…;;
うーん、std::stringにUTF-8の文字を入力するとダメっぽいでしょうか…?
取得したstd::stringをstd::wstringに変換してみましょう。
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
#include <iostream> #include <string> #include <codecvt> #include <boost/property_tree/xml_parser.hpp> int main() { // ロケール設定 std::wcout.imbue(std::locale("ja", std::locale::ctype)); boost::property_tree::ptree pt; boost::property_tree::xml_parser::read_xml("booklist.xml", pt); // UTF-8 を wchar_t に変換するコンバーター std::wstring_convert<std::codecvt_utf8<wchar_t>, wchar_t> cvt; // <book-list> <book> の属性"ISBN" を取得 if (boost::optional<long long> isbn = pt.get_optional<long long>("book-list.book.<xmlattr>.ISBN")) std::wcout << "ISBN : " << isbn << std::endl; // <book-list> <book> <title> を取得 if (boost::optional<std::string> title = pt.get_optional<std::string>("book-list.book.title")) std::wcout << "TITLE : " << cvt.from_bytes(title->c_str()) << std::endl; // <book-list> <book> <author> を取得 if (auto author = pt.get_optional<std::string>("book-list.book.author")) std::wcout << "AUTHOR : " << cvt.from_bytes(author->c_str()) << std::endl; return 0; } |
出力は問題なさそうですが、文字コード関連はもう少し勉強しないといけません…;;
要素を増やしてみる!
今までは1つの<book>タグしかありませんでしたが、これを複数増やしてループ処理を加えてみます。
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
<?xml version="1.0" encoding="utf-8"?> <book-list> <book ISBN="9784873117362"> <title>Effective Modern C++</title> <author>Scott Meyers</author> </book> <book ISBN="9784774185194"> <title>栢木先生の基本情報技術者教室</title> <author>栢木厚</author> </book> <book ISBN="9784103534327"> <title>騎士団長殺し</title> <author>村上春樹</author> </book> </book-list> |
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
#include <iostream> #include <string> #include <codecvt> #include <boost/property_tree/xml_parser.hpp> int main() { // ロケール設定 std::wcout.imbue(std::locale("ja", std::locale::ctype)); boost::property_tree::ptree pt; boost::property_tree::xml_parser::read_xml("booklist.xml", pt); // UTF-8 を wchar_t に変換するコンバーター std::wstring_convert<std::codecvt_utf8<wchar_t>, wchar_t> cvt; for (auto it : pt.get_child("book-list")) { if (auto isbn = it.second.get_optional<long long>("<xmlattr>.ISBN")) std::wcout << "ISBN : " << isbn << '\n'; if (auto title = it.second.get_optional<std::string>("title")) std::wcout << "TITLE : " << cvt.from_bytes(title->c_str()) << '\n'; if (auto author = it.second.get_optional<std::string>("author")) std::wcout << "AUTHOR : " << cvt.from_bytes(author->c_str()) << '\n'; } return 0; } |
今のところは問題なさそうですネ。
<book>タグが非常に多くなった場合の処理時間が少し気になるところでしょうか。
まとめ
そんなに難しいところではなかったのですが、文字コード関連や get_child() がどこを指しているのか(サンプルだと for 文で使用する it )、シンプルに考えて整理していかないといけない感じがしました。
XMLを設定ファイルとして利用したい場合は設定値を保持するクラス設計の方が頭を抱えそうですネ。